TERATEC 2023 – Thierry Leblond
1er juin 2023
Introduction
Historiquement toutes les solutions informatiques sont schématiquement construites sur une architecture web dite « trois tiers » :
- 1er tiers : un navigateur internet qui gère la présentation
- 2ème tiers : un serveur qui gère la requête et qui traite le processus et l’accès aux données
- 3ème tiers : une base de données qui gère les données
Dans un tel univers, on a longtemps traité la sécurité comme un sujet de maîtrise du périmétrique réseau : les gentils sont à l’intérieur du réseau d’entreprise et les méchants sont à l’extérieur. Quant à l’’internet, il est considéré du point de vue de la sécurité comme le mal absolu.
Avec l’arrivée depuis 20 ans des terminaux mobiles et la généralisation du Cloud, qui plus est avec l’accélération du télétravail depuis 2 ans, internet devient l’unique réseau professionnel. Les menaces sont grossièrement de trois natures :
- la confidentialité que le règlement général de protection des données a bien pris en main ;
- l’intégrité des données dont les rançongiciels sont la principale illustration aujourd’hui ;
- et enfin le plus grave pour la souveraineté des organisations, les lois extraterritoriales et le chalutage massif des données d’entreprises au profit d’États-espions.
Dans un monde où les données transitent en clair, il existe donc un vrai problème de sécurité propre au data. Que peut-on faire pour résoudre le problème ?
Thierry Leblond, CEO Scille Parsec
Des réglementations et des standards se profilent. J’en citerai trois parmi les plus récents :
- La directive européenne NIS2 sortie en décembre 2022 et applicable fin 2024 ;
- La stratégie Zero Trust du DoD US sortie en décembre 2022 et le standard zero trust NIST (National Institute of standards and technology) sorti en août 2020 ;
- La standardisation OTAN sur le Data Centric Security de 2020.
Nous en tirons assez rapidement les conséquences suivantes :
- la sécurité des données doit être gérée de manière crypto au plus près de l’utilisateur ;
- Cette protection crypto doit couvrir toutes les fonctions de sécurité de base: confidentialité, intégrité, non-répudiation, authenticité, anonymisation, traçabilité, historisation, révocation
Le monde de la protection cyber de bout-en-bout des données sensibles nous semble donc converger vers de nouveaux fondamentaux :
- Le principe de « zero trust » : « toujours vérifier et ne jamais faire confiance »
- Le principe de « zero knowledge » : encapsuler les données dans des enclaves cryptographiques garantissant toutes les fonctions de sécurité : confidentialité, intégrité, authenticité, traçabilité, historisation, révocation.
- L’approche de « Cypher Data Centric Security » consistant :
- à assurer la sécurité des données au plus près de l’utilisateur et du device ;
- à contrôler de manière cryptographique le cheminement des données entre les enclaves et les organisations et garantir le respect de la classification et des habilitations.
En quelques mots le chiffrement de bout-en-bout ou « end-to-end encryption » (E2EE) est en train de devenir une arme défensive cruciale au cœur des enjeux géopolitiques et de souveraineté à venir.
I) Le système d’information de M. tout le Monde
Quand on parle de cybersécurité informatique, il faut se poser la question du chemin d’attaque et des vulnérabilités du système. Où va se placer l’attaquant ?
Voici l’infrastructure de M. tout le Monde : les Utilisateurs Alice, Bob et Charlie travaillent sur des Devices qui communiquent avec les serveurs distants et les clouds distants en passant par des Réseaux soit internet soit périmétriques intranet.
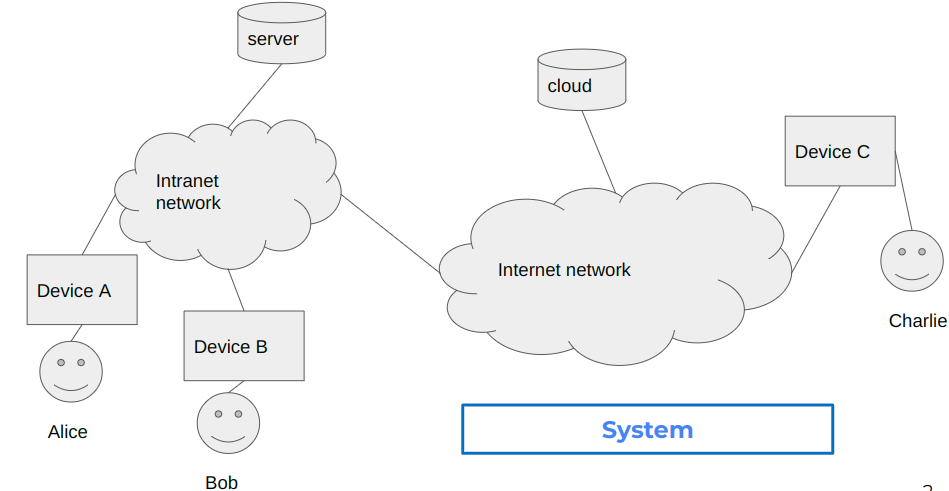
La première attaque vise les Utilisateurs : c’est le domaine de l’ingénierie sociale . Sur le plan technique, les parades sont l’authentification forte de type « Multi Factor Authentication » ou MFA avec toute la panoplie des solutions à base de biométrie, ou de token à usage unique. Ces technologies sont mûres.
La deuxième attaque vise les Devices : c’est le domaine des virus, des failles zero days. La parade arrive aujourd’hui grâce aux solutions de « End-Point Detection & Response » ou EDR ou de façon plus large les solutions XDR pour « Détection et Réponse étendues » . Elles désignent des outils SaaS qui apportent une sécurité globale et optimisée en intégrant des produits de sécurité dans des solutions simplifiées (incidents corrélés, analytique, détection et réponse automatisées, AI et machine learning et correction automatique des ressources affectées).
La troisième attaque vise les machines physiques dans les infrastructures et les clouds : ce sont les serveurs qui codent et stockent des datas. Quel niveau de confiance peut-on réellement avoir dans un service informatique, dans un prestataire de service ou dans mon infogéreur ou fournisseur de cloud, surtout s’il est soumis aux lois extraterritoriale de son pays ? Les données hébergées sur mon serveur qui accède potentiellement à toutes mes données sont-elles bien protégées de l’extérieur ?
La quatrième attaque passe par les réseaux internes et externes. Comment contrôler les requêtes réseau alors qu’elles peuvent potentiellement venir de n’importe où ? Une parade c’est le Zero Trust Network Access ou ZTNA qui peut astucieusement se marier avec des solutions VPN.
Enfin la cinquième attaque ce sont sur les data elles-mêmes. Ai-je vraiment confiance dans les sociétés privées qui exploitent les fibres intercontinentales ? Ai-je confiance dans mon infogéreur qui détient les clés de toutes mes données ? Ai-je confiance dans mon administrateur système « honnête mais curieux » ? Les autoroutes de l’information sont-elles écoutées par les « five eyes » ou par les routeurs 5G chinois ?
C’est là que PARSEC intervient en encapsulant les documents dans des enveloppes cryptographiques étanches aux attaques.
La stratégie Zero Trust du department of defense US illustre bien cette problématique globale avec ses sept piliers.

2) Le « Data Zero Trust ».
Les risques étant posés, nous nous concentrons maintenant exclusivement sur la problématique de la cyber protection de la donnée.
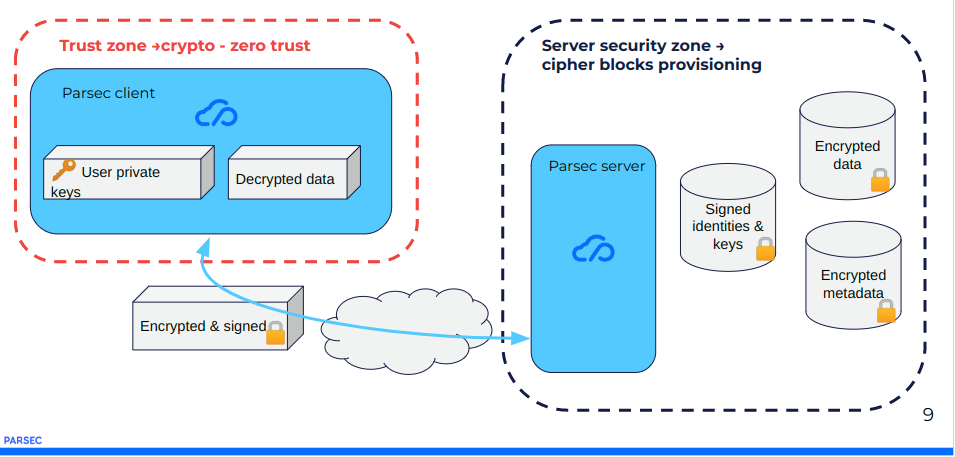
PARSEC fait un choix stratégique fondamental pour protéger les données : c’est de mettre de la signature et du chiffrement partout et sur chaque partage ou échange entre les clients PARSEC (acteurs humains ) et le serveurs (acteur non humain).
Chaque Utilisateurs génère et utilise ses propres clés de chiffrement et chaque device génère et utilise ses propres clés de signature :
- Les Données qui transitent entre deux devices sont systématiquement chiffrées de bout-en-bout
- Les Données qui sortent d’un device sont systématiquement signées
- Les Données entre le client et le serveur sont systématiquement signées
PROBLÈME N°1 : Comment distribuer facilement les clés ?
La signature et le chiffrement existent depuis 30 ans et l’invention de PGP la solution standard et utilisée par tous, c’est de passer par des certificats X509 délivrés par une autorité de certification. La difficulté de ce concept n’est pas le chiffrement en soit, mais le transfert des clés parce que l’utilisateur moyen n’a pas la capacité de comprendre ce qu’il fait quand il gère les clés et leurs transferts. Quand il va chercher la clé publique de son interlocuteur sur le serveur de clé PGP, comment sait-il vraiment que c’est la clé publique de la bonne personne ? En fait il n’en sait rien et pourtant il récupère malgré tout cette clé et l’utilise.
On a bien essayé de trouver une parade avec le « web of trust » qui est supposé créer un réseau de confiance en faisant signer les clés publiques par des tiers mais cela a été un échec parce que nous touchons la limite de la compréhension humaine : c’est trop compliqué et donc personne ne l’utilise. Théoriquement c’est viable mais pratiquement c’est inutilisable par un individu moyen.
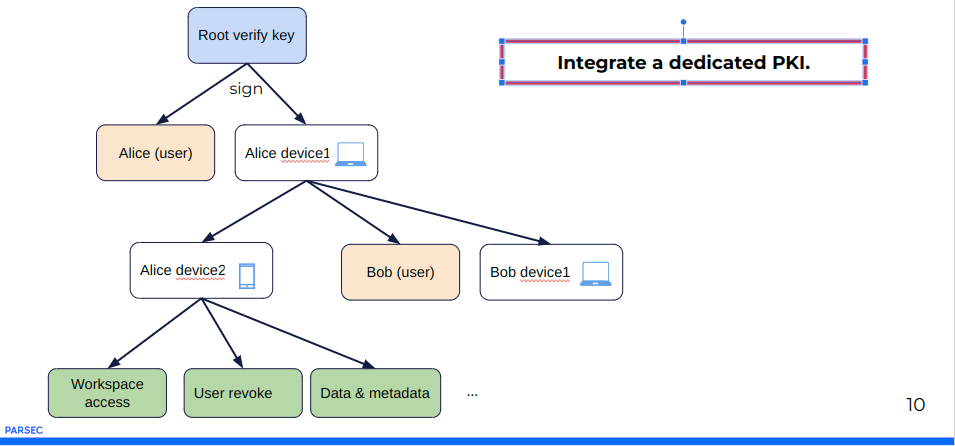
Notre réponse à ce problème a été d’intégrer le mécanisme de confiance dans l’application elle-même pour résoudre ce problème de complexité. C’est pourquoi PARSEC embarque une PKI dédiée. Le principe est très similaire à celui d’un système de PKI standard avec des processus d’enrôlement au moment de la remise du token et de sa signature. Mais ici, on ne passe plus par la PKI centrale : on intègre la PKI à l’application : c’est une « PKI clé en main ».
PROBLÈME N°2 : Comment fait-on pour construire la confiance initiale quand l’utilisateur enrôlé est inconnu ?
Nous avons fait le choix d’intégrer un mécanisme d’enrôlement passant un échange croisé de token secrets. C’est le mécanisme SAS pour « Short Authentication String ».
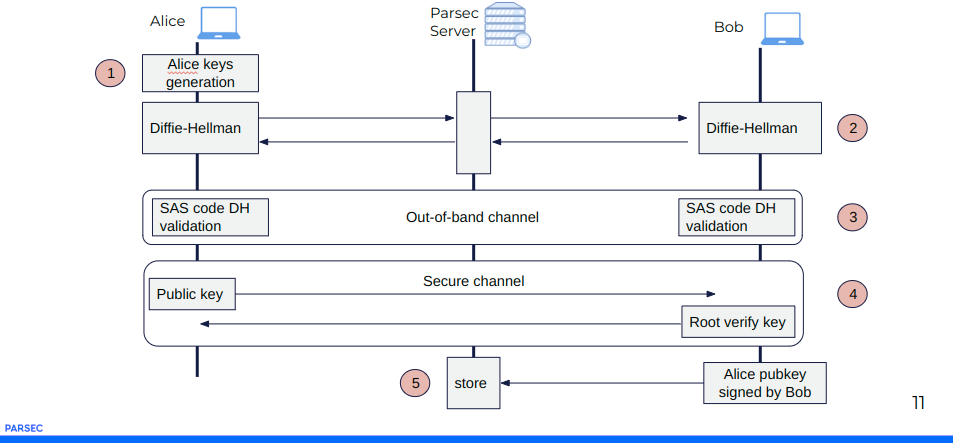
Du point de vue de l’utilisateur, cela se présente comme suit :
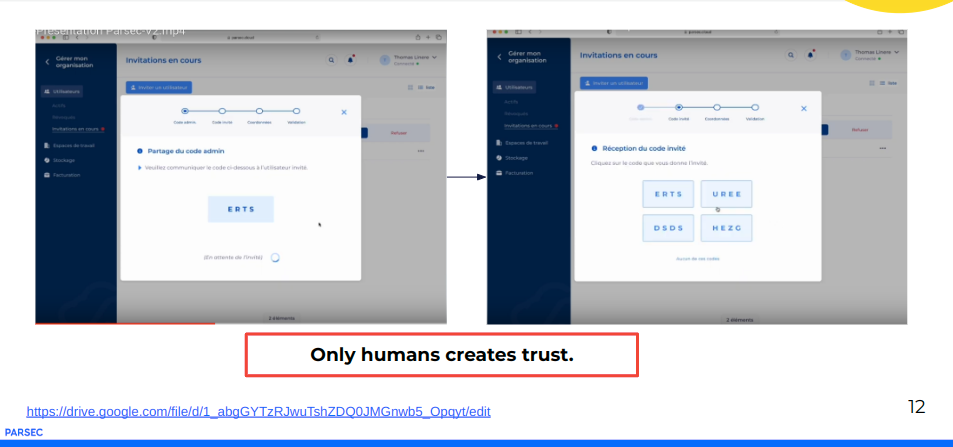
Le principe de base c’est que seul l’Humain crée la confiance et la crypto en est la garantie. C’est radicalement un principe d’ouverture de compte sur un serveur web distant.
PROBLÈME N°3 : Une fois qu’on a les clés, comment fait-on pour valider les données en mode Zero Trust ? C’est à dire toujours vérifier et ne jamais faire confiance.
Le système zero trust & zero knowledge de Parsec fonctionne à deux niveaux de sécurité :
- une sécurité cryptographique côté client qui gère l’enrôlement des utilisateurs et qui contrôle le déchiffrement et la vérification des signatures cryptographiques des documents d’une enclave donnée ;
- une sécurité côté serveur qui gère les droits des utilisateurs autorisés sur l’enclave.
Dans cette architecture radicalement nouvelle, le serveur remplit un « simple » rôle de routage de paquets chiffrés et signés.
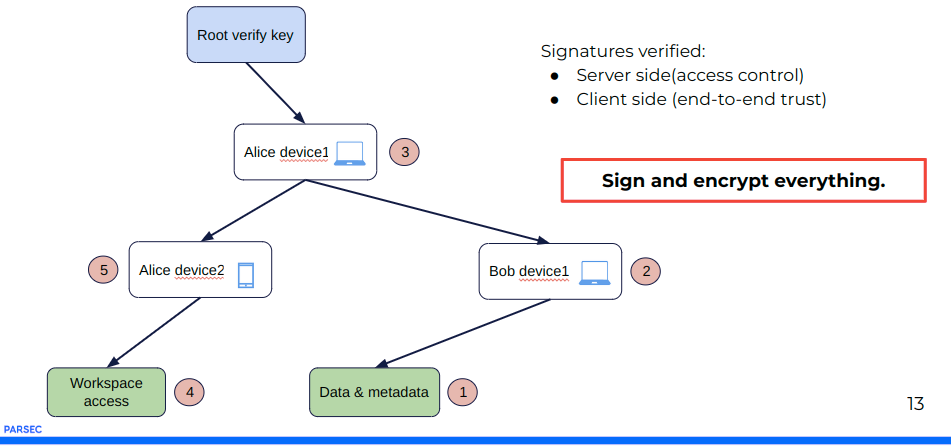
Chaque fois qu’une opération est faite, elle est signée donc on peut systématiquement la vérifier.
Cette vérification est faite :
- en terme de droit d’accès sur le serveur
- en bout en bout sur le client
PROBLÈME N°4 : Qu’est ce que la Data et à quel niveau granulaire doit-on travailler ?
On travaille généralement au niveau macroscopique du document, du fichier. C’est le cas quand on envoie par courriel chiffré par PGP un fichier en pièce jointe. C’est pratique, mais de moins en moins adapté car avec la multiplication des échanges, cela devient complexe à gérer : il faut chiffrer, déchiffrer, stocker localement, se synchroniser et enfin partager.
La réalité c’est que les systèmes sont de plus en plus intégrés et manipulent des données de plus en plus riches. Pour partager à plusieurs une donnée on envoie généralement un lien vers un flux de données. Le revers des choses, c’est que cela ne sécurise pas autant qu’une pièce jointe chiffrée.
La finitude de la donnée et sa représentation physique disparaissent complètement parce que les outils web modernes fournissent des fonctionnalités avancées. Le document disparaît donc aux profit de notion de service c’est à dire que techniquement le fichier est remplacé à un flux de données accessible par un lien URL.
Comment sécuriser les données ?
Il apparaît donc progressivement un besoin d’intégration de plus en plus fort entre la couche de sécurité et la couche applicative.
La réponse à ce problème nous est apparue en sécurisant (by design) l’entièreté de la solution et en abordant résolument la question au niveau des flux et non des documents. Les sécurités cryptographiques sont apportées par l’application elle-même.
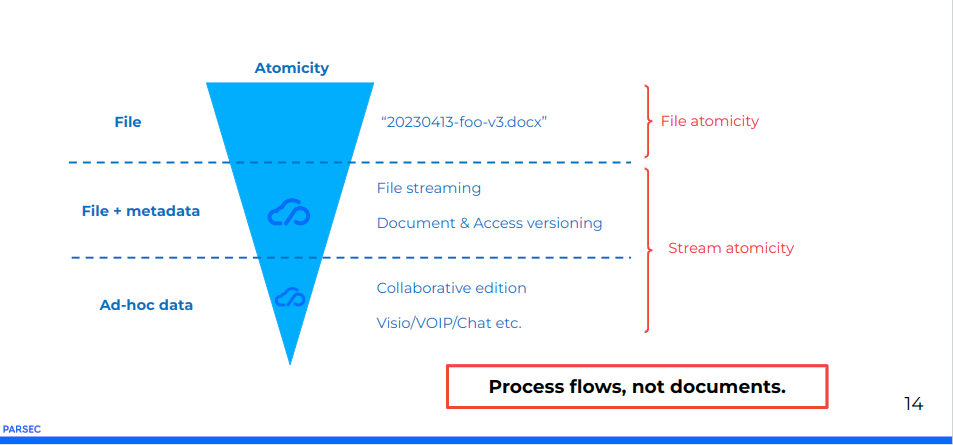
Ces problèmes étant résolus, nous sommes dès lors confrontés à des challenges très importants que nous avons pour la plupart résolus en cinq ans de travail acharné.
Challenge n°1 : La compatibilité ascendante sur les modèles de données.
Ce challenge est très bon exemple de verrou technique car la problématique de chiffrement de bout-en-bout exacerbe le problème de la compatibilité ascendante des données
Dans une application web classique le processus est simple : une mise à jour des fonctionnalités entraîne une évolution du modèle de données ce qui est trivial sur une base de données centralisée.
Mais dans une approche qui ne fait plus confiance au serveur central, comment ajouter une nouvelle fonction en compatibilité ascendante (par exemple celle de la classification des données en DCS) alors que toutes les données sont signées et chiffrées et que le serveur central ne voit rien ?
Challenge n°2 : Réaliser l’intégration forte de la sécurité dans l’application.
On peut illustrer ce challenge par un exemple simple : comment partager de très gros fichiers ?
Uploaded un fichier de 1 Mo de manière atomique c’est en effet facile à faire; mais uploaded un fichier de 1 Go c’est impossible d’où le choix assumé d’une atomicité au niveau du bloc de données.
Mais quand le serveur reçoit des blocs, quelle est la garantie qu’il va recevoir les autres blocs ou la table chiffrée qui réconcilie l’ensemble du document ? D’où une nouvelle consistant à résoudre la gestion atomique d’un gros document vu de l’utilisateur.
Challenge n°3 : comment gérer une décorrélation entre le système client et le système serveur ?
DÉFINITION : La cohérence éventuelle est la garantie que lorsqu’une mise à jour est effectuée dans une base de données distribuée, cette mise à jour sera finalement reflétée dans tous les nœuds qui stockent les données, ce qui se traduit par la même réponse à chaque fois que les données sont interrogées.
Un système web classique est composé d’un client navigateur web « bête » ou suiveur qui fait seulement de l’affichage et d’un serveur intelligent qui manipule les données.
Mais dans le modèle PARSEC, on doit gérer l’absence d’intelligence du serveur et reporter le traitement des données chiffrées au niveau du client. La conséquence, c’est qu’on doit pouvoir travailler avec des systèmes dé-corrélés et que « à la fin » ils doivent se mettre d’accord.
Comme le système client va aussi vite que l’utilisateur, à un moment, il y a obligatoirement une décorrélation entre les états du client et du serveur qu’il faut savoir gérer.
Si dans le cas du web classique, à chaque opération on doit parler au serveur, avec PARSEC on travaillera plutôt en local donc plus rapidement selon le cas d’usage tout en faisant son affaire d’une coupure réseau ou d’un faible débit car la corrélation se fait a posteriori par conception.
Le futur : l’intégration du principe de Data Centric Security et la gestion de la classification de sécurité.
L’idée générale du DCS consiste à brancher au fichier ou au document des métadonnées XML qui lui procurent des fonctionnalités de classification, de signature et de chiffrement conformes aux standards OTAN : ce sont les Stanag 4774 (Syntaxe des labels) et 4778 (Profils de labellisation).
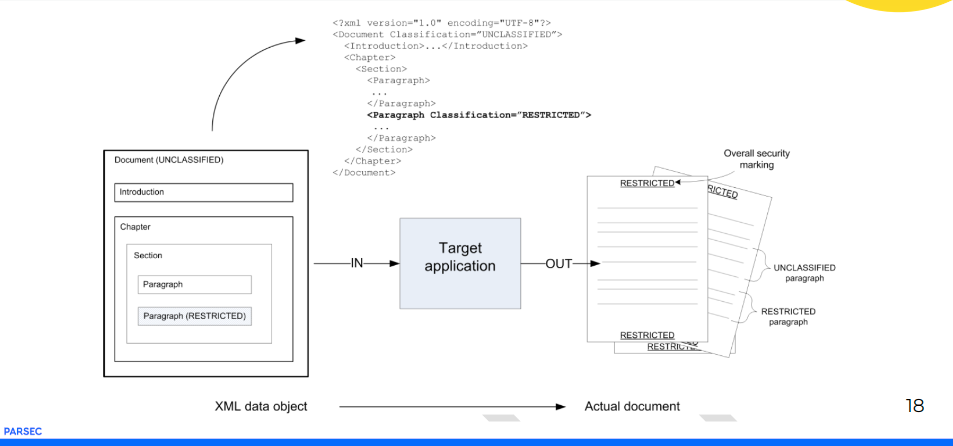
C’est une vision qui a des conséquences :
- 1) comme le zero trust doit accepter de s’appuyer sur des protocoles différents entre les partenaires il est nécessaire de disposer d’un format pivot pour garantir l’interopérabilité entre organisation via des formats standards.
- 2) Le DCS doit emporter des métadonnées qui seront caractéristiques des usages d’où standardisation des données et des formats de données pivot pour l’échange de données entre organisations.
Plus l’applicatif passe sous le contrôle de l’utilisateur, plus on va avoir des problèmes de compatibilité avec des formatages spécifiques selon l’organisation.
L’architecture proposée permet des échanges de flux de données au sein d’une organisation française.
L’architecture proposée en inter-nations comprend deux interfaces :
- une passerelle « Parsec-to-DCS gateway » qui assure l’export des documents au formats DCS.
- Un serveur d’identité PKI dédié Parsec (auto-enrôlement) interconnecté avec la PKI de l’organisation interne ou partenaire (enrôlement délégué à la PKI centrale).
Reste une problématique centrale celle de la classification du partage des flux données en flux car le standard DCS OTAN est orienté document et non flux.
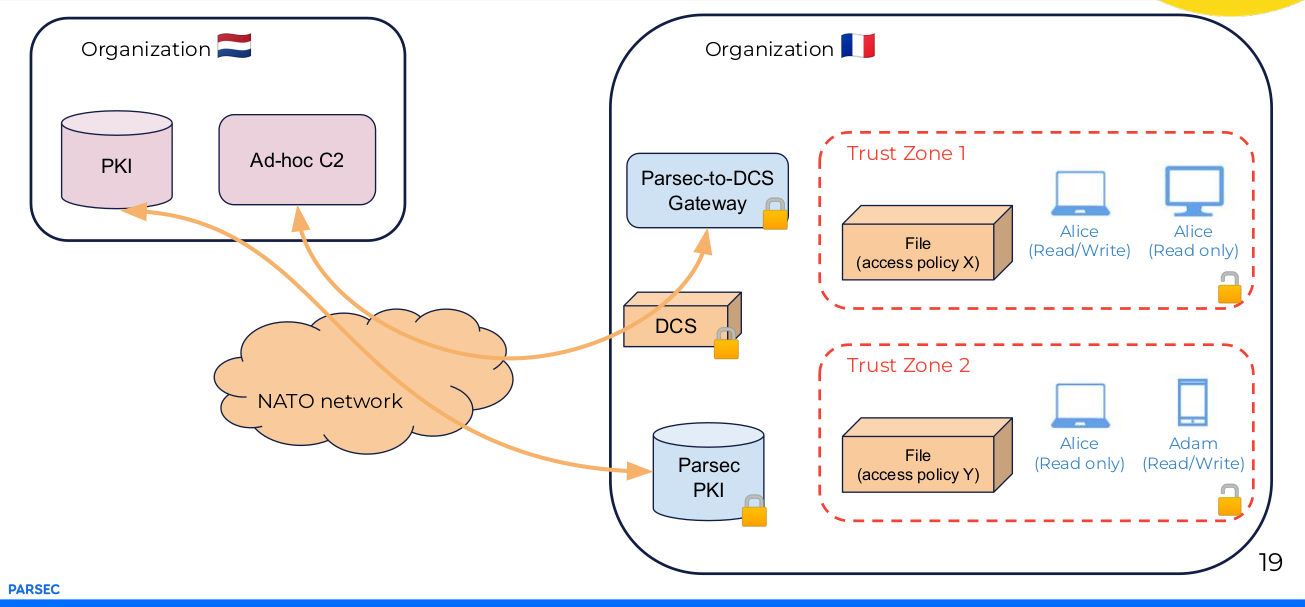
Dans ce cas, la solution est d’adopter une solution applicative unique orientée flux au niveau des nations.
Conclusion
Le système PARSEC est nativement en capacité de supporter la compatibilité avec le Data Centric Security DCS et même au-delà, il permet de gérer des fonctionnalités beaucoup plus avancées entre les différents acteurs qui utilisent PARSEC.
On pourra par exemple labelliser du flux ce qui n’est pas possible avec le pivot DCS prévu pour le document unitaire.


